由于Log-Structured结构,F2FS文件系统的可用空间会快速被消耗,因此需要引入垃圾回收(GC)来回收空间。
本源码阅读主要为个人阅读F2FS GC源码过程中的记录,主要介绍以下内容。
- 介绍f2fs gc的主体流程
- 介绍victim segment选择策略(涉及一定的SSR机制相关的内容)
- 【当前】介绍GC的执行过程
在每部分内容中,会对涉及的关键数据结构进行阅读与记录,并分析函数的执行流程与若干细节。
do_garbage_collect函数(对选定segment进行垃圾回收)
在f2fs_victim_select函数找到对应的victim segno后,将使用do_garbage_collect函数对这个segno进行垃圾回收,对不同segment类型(node/data)分别使用不同的策略,对segment中的有效块进行数据迁移,并修改对应的映射信息(如dnode/inode的data block指针对应的信息等)。
1. 涉及的重要数据结构
1.1 F2FS summary
一般情况下,我们可以根据nid找到一个块的物理地址,但是有时(如GC的情况下)我们也需要通过物理地址反向找到该块对应的node信息,并根据GC结果更新该node的信息(如数据迁移后,物理地址改变)
-
功能: 提供通过数据块物理地址找到所属node(nid)的能力
-
每个
f2fs_summary_block保存512个f2fs_summary,系统可以根据segno找到对应的f2fs_summary_block,再找到对应的f2fs_summary一个segment(2MB)最多可存储512个block(4KB),因此一个segment对应一个
f2fs_summary_blocksegment中每个block都对应一个entry,记录了block所属的node(nid),以及是这个node的第几个block(ofs_in_node)
-
f2fs_summary_block还保存了f2fs_journal(缓存SIT和NAT的一些改动,避免频繁读写)和summary_footer(用于指示当前保存的是node还是data数据)
// usr/local/include/f2fs_fs.h
struct f2fs_summary {
__le32 nid; /* parent node id */
union {
__u8 reserved[3];
struct {
__u8 version; /* node version number */
__le16 ofs_in_node; /* block index in parent node */
} __packed;
};
} __packed;
struct f2fs_summary_block {
struct f2fs_summary entries[ENTRIES_IN_SUM]; // ENTRIES_IN_SUM=512
struct f2fs_journal journal;
struct summary_footer footer;
} __packed;
struct summary_footer {
unsigned char entry_type; /* SUM_TYPE_XXX */
__le32 check_sum; /* summary checksum */
} __packed;
f2fs_summary在GC的作用: 当选择出需要gc的victim segment之后,可以通过这个victim segment的segno,在SSA区域找到 f2fs_summary_block。对victim segment的每一个block进行迁移的时候,会根据block的地址在 f2fs_summary_block 找到 它所对应的f2fs_summary 然后根据它所记录的 f2fs_summary->nid 以及 f2fs_summary->ofs_in_node 找到对应的具体的block的数据,然后将这些数据设置为dirty,然后等待vfs的writeback机制完成页迁移。
1.2 node_info
存储node 的相关信息,如nid、所属inode号、node block地址、版本号等
struct node_info {
nid_t nid; /* node id */
nid_t ino; /* inode number of the node's owner */
block_t blk_addr; /* block address of the node */
unsigned char version; /* version of the node */
unsigned char flag; /* for node information bits */
};
该结构体主要通过f2fs_get_node_info函数获取信息,主要是通过node对应的nid,在NAT中找到对应的entry,并读取出node信息。
struct node_info ni;
err = f2fs_get_node_info(fio.sbi, dn.nid, &ni, false);
具体来说,f2fs_get_node_info函数经过以下步骤:
- 在NAT cache中查找nid对应的表项,若命中则填充
ni的信息 - 尝试获取
curseg_info的journal的读写信号量,避免干扰CP - 通过
current_nat_addr(sbi, nid)函数获取nid对应表项在NAT block的位置index,并读取nat block - 通过nid,从nat block上获取相应的nat entry,并根据entry,将NAT表项中的信息填充
ni
1.3 f2fs_node
-
存储node类型
-
node_footer中存储node相关信息(nid及其他标记)
-
node_footer记录该node的id号、所属inode号
-
flag是复合结构
-
包括cold/fsync/dentry标记
-
offset: 该node的逻辑地址(请注意是逻辑地址)
通过该字段可以确认该node在inode的哪个位置,也就是层级关系
-
-
struct f2fs_node {
/* can be one of three types: inode, direct, and indirect types */
union {
struct f2fs_inode i;
struct direct_node dn;
struct indirect_node in;
};
struct node_footer footer;
};
struct node_footer {
__le32 nid; /* node id */
__le32 ino; /* inode nunmber */
__le32 flag; /* include cold/fsync/dentry marks and offset(逻辑地址) */
__le64 cp_ver __attribute__((packed)); /* checkpoint version */
__le32 next_blkaddr; /* next node page block address */
};
1.4 f2fs_inode
在论文中,F2FS inode结构如下所示
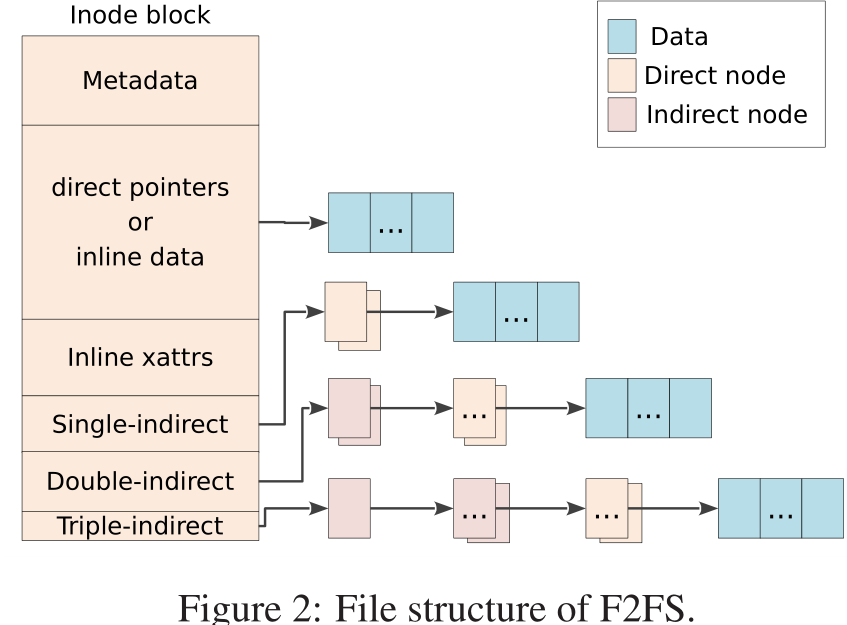
struct f2fs_inode {
...
union {/* 最多记录923个data block地址和5个nid,其中2个direct node,2个indirect node, 1个double indirect node */
...
__le32 i_addr[DEF_ADDRS_PER_INODE]; /* Pointers to data blocks */
};
__le32 i_nid[DEF_NIDS_PER_INODE]; /* direct(2), indirect(2), double_indirect(1) node id */
} __packed;
1.5 f2fs_io_info(实例名一般为fio)
该结构体是 F2FS 写流程最重要的数据结构,一般在 写data接口 中被使用。
其中,在写流程中,最重要的两个参数是new_blkaddr(新写入的地址)和old_blkaddr(原本的地址)
拓展:F2FS-NOTES/Reading-and-Writing/写流程.md at master · RiweiPan/F2FS-NOTES (github.com)
struct f2fs_io_info {
struct f2fs_sb_info *sbi; /* f2fs_sb_info pointer */
nid_t ino; /* inode number */
enum page_type type; /* contains DATA/NODE/META/META_FLUSH */
enum temp_type temp; /* contains HOT/WARM/COLD */
enum req_op op; /* contains REQ_OP_ */
blk_opf_t op_flags; /* req_flag_bits */
block_t new_blkaddr; /* new block address to be written */
block_t old_blkaddr; /* old block address before Cow */
struct page *page; /* page to be written */
struct page *encrypted_page; /* encrypted page */
struct page *compressed_page; /* compressed page */
struct list_head list; /* serialize IOs */
unsigned int compr_blocks; /* # of compressed block addresses */
unsigned int need_lock:8; /* indicate we need to lock cp_rwsem */
unsigned int version:8; /* version of the node */
unsigned int submitted:1; /* indicate IO submission */
unsigned int in_list:1; /* indicate fio is in io_list */
unsigned int is_por:1; /* indicate IO is from recovery or not */
unsigned int retry:1; /* need to reallocate block address */
unsigned int encrypted:1; /* indicate file is encrypted */
unsigned int post_read:1; /* require post read */
enum iostat_type io_type; /* io type */
struct writeback_control *io_wbc; /* writeback control */
struct bio **bio; /* bio for ipu */
sector_t *last_block; /* last block number in bio */
};
1.6 dnode_of_data
struct dnode_of_data {
struct inode *inode; /* VFS inode结构 */
struct page *inode_page; /* f2fs_inode对应的node page */
struct page *node_page; /* 用户需要访问的物理地址所在的node page,有可能跟inode_page一样*/
nid_t nid; /* 用户需要访问的物理地址所在的node的nid,与上面的node_page对应*/
unsigned int ofs_in_node; /* 用户需要访问的物理地址位于上面的node_page对应的addr数组第几个位置 */
bool inode_page_locked; /* inode page is locked or not */
bool node_changed; /* is node block changed */
char cur_level; /* 当前node_page的层次,按直接访问或者间接访问的深度区分 */
char max_level; /* level of current page located */
block_t data_blkaddr; /* 用户需要访问的物理地址 */
};
-
该结构体主要用于F2FS的物理地址寻址,在GC中,主要在data segment gc时的
f2fs_do_write_data_page函数中调用,利用该结构体能够得到block的物理地址,将数据读取出来。-
大部分情况下,仅需传入inode进行初始化
if (f2fs_is_atomic_file(inode)) set_new_dnode(&dn, F2FS_I(inode)->cow_inode, NULL, NULL, 0); else set_new_dnode(&dn, inode, NULL, NULL, 0); -
根据需要访问的page->index,执行
f2fs_get_dnode_of_data寻址err = f2fs_get_dnode_of_data(&dn, page->index, type); // type类型影响了寻址的行为 block_t blkaddr = dn.data_blkaddr; // 获得对应位置的物理地址信息
-
-
在异地更新步骤中,进行了物理地址分配、写入数据、无效旧地址数据后,需要更新LBA-PPA的映射关系,在
f2fs_update_data_blkaddr(dn, blkaddr)中更新,主要涉及data_blkaddr,node_page两个成员(即更新data block地址以及direct node(有可能同时也是inode)中的地址信息)
拓展:更多关于f2fs_get_dnode_of_data函数的信息,可参考以下链接:https://github.com/RiweiPan/F2FS-NOTES/blob/master/ImportantDataStructure/get_dnode.md
1.7 curseg_info
F2FS中的active segment也称curseg
curseg_info表示当前使用的segment的信息。F2FS同时运行着6个curseg_info(HOT/WARM/COLD x NODE/DATA)
/* for active log information */
struct curseg_info {
struct mutex curseg_mutex; /* lock for consistency */
struct f2fs_summary_block *sum_blk; /* cached summary block */
struct rw_semaphore journal_rwsem; /* protect journal area */
struct f2fs_journal *journal; /* cached journal info */
unsigned char alloc_type; /* current allocation type */
unsigned short seg_type; /* segment type like CURSEG_XXX_TYPE */
unsigned int segno; /* current segment number */
unsigned short next_blkoff; /* next block offset to write */
unsigned int zone; /* current zone number */
unsigned int next_segno; /* preallocated segment */
int fragment_remained_chunk; /* remained block size in a chunk for block fragmentation mode */
bool inited; /* indicate inmem log is inited */
};
f2fs_summary_block:1.1已经介绍过,存储当前segment中所有block的f2fs_summary信息,能够反向寻找node、偏移等信息。f2fs_journal:记录每个block是否有效,记录所管理的block是否被分配出去
curseg_info作用:当需要分配一个新的block时,会根据block类型,在curseg_info中选取一个segment,在该segment上分配新的block,并将映射信息写入f2fs_summary_block和f2fs_journal中。让大部分的元数据更新都放在curseg_info中,防止频繁读写盘。
2. do_garbage_collect函数(数据迁移)
在f2fs_victim_select函数找到对应的victim segno后,将使用do_garbage_collect函数对这个segno进行垃圾回收
-
循环找到segno对应的f2fs summary page,并且unlock这些pages
(默认情况下,即segment大小与section大小相同的情况下,就是寻找segno对应的segment)
-
若segment中没有有效块了,则无需进行数据迁移,直接转到free步骤,不再迁移
-
若sum_page未被读到内存中,或f2fs cp错误,则不再迁移
-
判断SSA中记录的类型与SIT表记录的类型是否一致,不一致的话说明系统一致性出了问题,需要执行FSCK修复,且不再迁移
-
到这一步仍没有问题时,按照segment类型分别进行GC/数据迁移,并更新统计信息,如下
/* 根据segment类型进行gc,返回结果增加到submitted中 */ if (type == SUM_TYPE_NODE) submitted += gc_node_segment(sbi, sum->entries, segno, gc_type); else submitted += gc_data_segment(sbi, sum->entries, gc_list, segno, gc_type, force_migrate); /* 暂时是空宏,语句为do{}while(0) */ stat_inc_seg_count(sbi, type, gc_type); /* 更新super block信息,对应gc_mode(前台/后台)回收seg数量++ */ sbi->gc_reclaimed_segs[sbi->gc_mode]++; migrated++; -
已经完成数据迁移后,更新统计信息seg_freed(do_garbage_collect函数返回值)
注意:仅有FGGC关心该信息,BGGC不统计该信息。
其中,步骤5中按照block类型(node/data)分别进行GC/数据迁移
2.1 gc_node_segment:对node segment进行GC
在do_garbage_collect过程中,会根据segment的类型(node/data)进行不同的处理
gc_node_segment即对应处理node segment的GC情况
2.1.1 gc_node_segment(fs/f2fs/gc.c)
功能:将node segment中的node block地址与NAT中的nid->node block地址比对
- 若node block有效,则按照COLD进行迁移
- 否则node block无效,无需处理
此函数遍历segment中的所有block,并跳过无效块(无需迁移数据),对每个遍历的有效块包含3个Phase,其中Phase 0与Phase 1为数据预读步骤,保证进行阶段2时数据已经在内存中
if (phase == 0) {
f2fs_ra_meta_pages(sbi, NAT_BLOCK_OFFSET(nid), 1,
META_NAT, true);
continue;
}
/* phase 1*/
if (phase == 1) {
f2fs_ra_node_page(sbi, nid);
continue;
}
/* phase 2*/
node_page = f2fs_get_node_page(sbi, nid);
...
err = f2fs_move_node_page(node_page, gc_type);
if (!err && gc_type == FG_GC)
submitted++;
-
Phase 0:将NAT中,nid对应的元数据页预读到内存中
-
Phase 1:根据
struct f2fs_summary entry中记录的nid,将相应的node page预读到内存中 -
Phase 2:对读取到内存中的页进行数据迁移(调用
f2fs_move_node_page函数)若干细节:
-
调用
f2fs_get_node_info(sbi, nid, &ni, false)获取node信息存储到struct node_info ni中,false表示不需要读盘
-
读取到内存后还需要检查一次当前nid对应的blk_addr与当前遍历的block的地址是否一致,避免在读取到内存的过程中,node block addr已经发生改变
-
只有FGGC关注submitted等回收统计信息,而BGGC不关心
-
2.1.2 f2fs_move_node_page(fs/f2fs/node.c)
功能:对指定的block/page进行数据迁移
该函数由gc_node_segment调用,分为FGGC情况与BGGC情况
-
FGGC下,node_page写回(前台GC需要马上分配新的位置,将旧的位置腾出)
- 调用
f2fs_wait_on_page_writeback函数等待写回 -
调用
set_page_dirty将页设置为脏页 -
调用函数
clear_page_dirty_for_io(/mm/page_writeback.c)写回拓展:clear_page_dirty_for_io: Linux 深入理解脏页(dirty page)_私房菜的博客-CSDN博客
拓展:wait_on_page_writeback:wait_on_page_bit (cnblogs.com)
-
调用函数
__write_node_page进行page write其中调用的关键函数
f2fs_do_write_node_page(nid, &fio)间接调用的关键函数为
do_write_page函数(在data block迁移中同样调用该函数),分配新的物理地址、设置旧物理地址为脏。并通过bio提交,将数据写入新的地址。更新f2fs_summary信息,分配new_blkaddr,进行node page迁移
-
f2fs_allocate_data_block接口(定义于/fs/f2fs/segment.c)- 函数首先会根据type获得CURSEG。然后在CURSEG分配一个新的物理块,然后将旧的物理块无效掉。
- 将已经搬完的segment放入到PRE链表,而不马上使用(避免一致性问题),需要经过一次CP后,将PRE中的节点释放之后,才被真正地使用
更多关于函数
f2fs_allocate_data_block的内容,可阅读:F2FS-NOTES/Reading-and-Writing/写流程.md at master · RiweiPan/F2FS-NOTES (github.com)
-
- 调用
-
BGGC下,仅需设定node page为脏,等待定期下刷即可
// BGGC情况 if (!PageWriteback(node_page)) set_page_dirty(node_page);
2.2 gc_data_segment:对data segment进行GC
与gc_node_segment类似,对data segment进行GC,但与node segment的操作(三个阶段)略有不同。data segment的gc操作需要进行五个阶段。这是因为data进行搬移之前,首先需要找到所属的inode与dnode,在迁移时需要修改这些inode/dnode的信息。其次,data segment的gc操作还要区分普通页和特殊页(加密、压缩、需要校验的页)
2.2.1 gc_data_segment(fs/f2fs/gc.c)
与gc_node_segments类似的数据结构以及操作不再赘述。
遍历segment中的block,对于每个有效块,共进行五个阶段的操作:
-
Phase 0:将NAT中,nid对应的元数据页预读到内存中
-
Phase 1:根据
struct f2fs_summary entry中记录的nid,将相应的node page(dnode)预读到内存中同时,利用
is_alive函数获取dnode所属的inode信息(返回值存储到struct node_info dni中)/**此处获取了dnode所属的inode号(存储在dni.ino中)以及dnode在inode中的逻辑偏移(存储在nofs中) * 若data block的上一层就是inode,则dni就是该inode的node info,dni.ino就是当前inode的ino号 * 若data block的上一层是dnode,则dni是dnode的node info,dni.ino是当前dnode所属的ino号 */ /* 内部通过调用f2fs_get_node_info函数获得node_info,存储至dni中,dni.ino即为所属inode的信息 */ if (!is_alive(sbi, entry, &dni, start_addr + off, &nofs)) continue; -
Phase 2:根据
dni.ino得到dnode所属的inode号,并将相应的node page(inode)与预读到内存中同时获取当前data block在父母dnode/inode的偏移
ofs_in_node -
Phase 3:对得到的inode进行若干判断,判断是否能够将当前inode加入gc_list(同样是预读步骤)
-
若文件是pinned file,且模式是FGGC的情况下,不将该inode加入gc_list,直接返回
-
计算当前data block所在的inode的逻辑地址偏移
计算方法:start_bidx存储当前data block所在inode的逻辑偏移(即当前data block是inode上的第几个data block)
start_bidx = f2fs_start_bidx_of_node(nofs, inode) + ofs_in_node; /*f2fs_start_bidx_of_node:通过给定的inode以及nofs(当前dnode在inode上的逻辑偏移) 计算出dnode存储的第一个表项(data block地址)所在的block偏移*/ -
根据start_bidx预读data page到内存中,若成功读取,则将inode加入gc_list
其中,读取data page需要区分普通页和特殊页(加密、压缩、需校验的页),分别调用不同的接口
- 特殊页:
ra_data_block(inode, start_bidx) - 普通页:
f2fs_get_read_data_page(inode, start_bidx, REQ_RAHEAD, true, NULL)
- 特殊页:
-
-
Phase 4:从gc_list中读取inode,并且根据普通页和特殊页,分别进行处理
-
特殊页:调用
move_data_block接口该函数使用META_MAPPING来搬移,使得用户无法获取到其原数据(特殊页的原数据对用户不可见,因此如果通过写data接口写入,需要重新解密和加密) 因此通过直接拷贝的方式写入。
//仅列出关键步骤 static int move_data_block(struct inode *inode, block_t bidx,int gc_type, unsigned int segno, int off){ ... /* 步骤1: 获取特殊页数据 */ mpage = f2fs_grab_cache_page(META_MAPPING(fio.sbi),fio.old_blkaddr, false); ... /* 步骤2: 分配新地址,并用newaddr存储,将加密页的地址指向newaddr所对应的page */ f2fs_allocate_data_block(fio.sbi, NULL, fio.old_blkaddr, &newaddr, &sum, type, NULL);//传入参数page、fio为NULL fio.encrypted_page = f2fs_pagecache_get_page(META_MAPPING(fio.sbi), newaddr, FGP_LOCK | FGP_CREAT, GFP_NOFS); ... /* 步骤3: 拷贝mpage的数据到fio.encrypted_page中 */ memcpy(page_address(fio.encrypted_page),page_address(mpage), PAGE_SIZE); ... /* 步骤4: 提交到bio */ fio.op = REQ_OP_WRITE; fio.op_flags = REQ_SYNC; fio.new_blkaddr = newaddr; f2fs_submit_page_write(&fio); //在f2fs_submit_page_write函数中,若fio.encrypted_page非空,则会将bio->page设定为fio.encrypted_page, 而非fio.page。从而实现提交加密页,而非普通页 ... /* 步骤5: 重新建立映射,更新dn->data_blkaddr信息,并更新到f2fs_inode或direct_node中 */ f2fs_update_data_blkaddr(&dn, newaddr); } -
普通页:调用
move_data_page接口与node segment中
f2fs_move_node_page的方法类似,定义struct f2fs_io_info fio实例,通过f2fs_do_write_data_page函数执行(F2FS 写流程中的关键函数之一)其中关键的函数为
f2fs_do_write_data_page:这个函数的作用是根据系统的状态选择就地更新数据(inplace update)还是异地更新数据(outplace update)。一般情况下,系统只会在磁盘空间比较满的时候选择就地更新策略,避免触发过多的gc影响性能。(见2.2.2)
-
大概总结一下,Phase 0、1、2、3阶段都是数据预读阶段,需要得到data block所属的inode,以及该data block在inode中的偏移量。在Phase 4中,根据data block的类型(特殊页/普通页)分别进行相应的数据迁移操作,其中加密页通过MMAP+数据拷贝的方式,将加密页搬迁到新地址;普通页数据迁移分为异地更新和就地更新两种方案。在进行数据迁移后,更新映射信息。
一些可能的疑问:在上述过程中,读取了data block所属的dnode 和inode 的信息,但是在对当前data block进行数据迁移之后,在哪个步骤修改了inode和dnode的信息?
答:无论是move_data_block还是move_data_page,都会直接或间接调用函数f2fs_update_data_blkaddr,该函数修改映射关系、inode信息与dnode信息等,这些是无需GC步骤关心的,只要调用即可。
2.2.2 f2fs_do_write_data_page (fs/f2fs/data.c)
相关阅读:F2FS-NOTES/Reading-and-Writing/写流程.md at master · RiweiPan/F2FS-NOTES (github.com)
上面这篇源码解读中已经解释的比较清楚,后续F2FS的代码更新没有修改这部分的关键核心逻辑。
简单总结一下:f2fs_do_write_data_page(struct f2fs_io_info *fio)函数根据系统的状态,选择异地更新(outplace update)还是就地更新(inplace update)策略。一般仅在磁盘空间较满时选择就地更新策略。
-
异地更新策略逻辑
f2fs_outplace_write_data(fs/f2fs/segment.c)- 分配一个新的物理地址
- 将数据写入新的物理地址
- 将旧物理地址无效、等待GC回收
- 更新逻辑地址和物理地址的映射关系
其中,1~3步骤在
do_write_page(&sum, fio)函数中完成;static void do_write_page(struct f2fs_summary *sum, struct f2fs_io_info *fio) { int type = __get_segment_type(fio); // 获取数据类型,这个类型指HOT/WARM/COLD X NODE/DATA的六种类型 f2fs_allocate_data_block(fio->sbi, fio->page, fio->old_blkaddr, &fio->new_blkaddr, sum, type, fio, true); // 分配新地址,将旧地址设置为脏 f2fs_submit_page_write(fio); //提交bio }其次,4步骤通过
f2fs_update_data_blkaddr(dn, fio->new_blkaddr)重新建立映射,更新dn->data_blkaddr信息,并更新到f2fs_inode或direct_node中(根据dn中的结构)。此外,还创建新的f2fs summary来记录其版本号、偏移量、上一级nid等
-
就地更新策略
f2fs_inplace_write_data(fs/f2fs/segment.c)-
将新地址和旧地址保持一致(这也说明这个函数应该只用于数据更新写/GC,而不会被SSR机制使用)
fio->new_blkaddr = fio->old_blkaddr -
将数据通过bio,写入原本的地址,且无需更新映射关系
f2fs_inode、direct_node信息无需修改,因为blkaddr没有发生改变,仅修改了block信息
-
2.2.a f2fs_get_dnode_of_data(补充)
该函数的功能主要是获取data block的物理地址,并将信息存储到dn.data_blkaddr中
int f2fs_get_dnode_of_data(struct dnode_of_data *dn, pgoff_t index, int mode)
{
struct f2fs_sb_info *sbi = F2FS_I_SB(dn->inode);
struct page *npage[4];
struct page *parent = NULL;
int offset[4];
unsigned int noffset[4];
nid_t nids[4];
int level, i = 0;
int err = 0;
// 通过计算得到offset, noffset,从而知道位于第几个node page的第几个offset对应的物理地址中
level = get_node_path(dn->inode, index, offset, noffset);
if (level < 0)
return level;
nids[0] = dn->inode->i_ino;
npage[0] = dn->inode_page;
if (!npage[0]) {
npage[0] = f2fs_get_node_page(sbi, nids[0]); // 获取inode对应的f2fs_inode的node page
}
parent = npage[0];
if (level != 0)
nids[1] = get_nid(parent, offset[0], true); // 获取f2fs_inode->i_nid
dn->inode_page = npage[0];
dn->inode_page_locked = true;
for (i = 1; i <= level; i++) {
bool done = false;
if (!nids[i] && mode == ALLOC_NODE) {
// 创建模式,常用,写入文件时,需要node page再写入数据,因此对于较大文件,在这里创建node page
if (!f2fs_alloc_nid(sbi, &(nids[i]))) { // 分配nid
err = -ENOSPC;
goto release_pages;
}
dn->nid = nids[i];
npage[i] = f2fs_new_node_page(dn, noffset[i]); // 分配node page
// 如果i == 1,表示f2fs_inode->nid[0~1],即direct node,直接赋值到f2fs_inode->i_nid中
// 如果i != 1,表示parent是indirect node类型的,要赋值到indirect_node->nid中
set_nid(parent, offset[i - 1], nids[i], i == 1);
f2fs_alloc_nid_done(sbi, nids[i]);
done = true;
} else if (mode == LOOKUP_NODE_RA && i == level && level > 1) {
// 预读模式,少用,将node page全部预读出来
npage[i] = f2fs_get_node_page_ra(parent, offset[i - 1]);
done = true;
}
if (i == 1) {
dn->inode_page_locked = false;
unlock_page(parent);
} else {
f2fs_put_page(parent, 1);
}
if (!done) {
npage[i] = f2fs_get_node_page(sbi, nids[i]); // 根据nid获取node page
}
if (i < level) {
parent = npage[i]; // 注意这里parent被递归地赋值,目的是处理direct node和indrect node的赋值问题
nids[i + 1] = get_nid(parent, offset[i], false); // 计算下一个nid
}
}
// 全部完成后,将结果赋值到dn,然后退出函数
dn->nid = nids[level];
dn->ofs_in_node = offset[level];
dn->node_page = npage[level];
dn->data_blkaddr = datablock_addr(dn->inode, dn->node_page, dn->ofs_in_node); // 这个就是根据page index所得到的物理地址
return 0;
}
2.3 data/node segment中途退出当前gc的判断条件的区别
-
在进行gc_node_segment、gc_data_segment时,遍历每个block时都会进行条件判断,是否需要暂停当前的GC工作。而对于node segment和data segment,判断条件会略有不同。
/* 1.gc_node_segment */ /* stop BG_GC if there is not enough free sections. */ if (gc_type == BG_GC && has_not_enough_free_secs(sbi, 0, 0)) return submitted; /* 2.gc_data_segment */ /* * stop BG_GC if there is not enough free sections. * Or, stop GC if the segment becomes fully valid caused by * race condition along with SSR block allocation. */ if ((gc_type == BG_GC && has_not_enough_free_secs(sbi, 0, 0)) || (!force_migrate && get_valid_blocks(sbi, segno, true) == CAP_BLKS_PER_SEC(sbi))) return submitted;-
对于node segment,仅在后台GC,且可用free空间不足时,暂停当时的后台GC(转而进行前台GC)
-
对于data segment,除了上述的情况,还需要额外判断SSR的块分配的情况
- 若当前不是force_migrate(gc_control->should_migrage_blocks)
- 由于SSR的使用,当前正在进行GC的segment被争用为SSR选取的segment,并写入了新的数据,使得当前segment全为有效块,此时不再回收当前的segment。
-
-
另外,SSR机制下的数据写入使用就地更新策略,而在就地更新函数
f2fs_inplace_write_data中,有一段判断条件,如下所示。由逻辑可看出,就地更新函数只能作用在data segment中。(后来发现SSR调用的应该不是这个函数,因为该异地更新函数中直接有
fio->new_blkaddr = fio->old_blkaddr;的字段,这明显不符合SSR机制的策略(这里的就地更新策略应该只针对更新写,而SSR机制应该主要是追加写/新写))segno = GET_SEGNO(sbi, fio->new_blkaddr);// 获取需要进行IPU的segment号 if (!IS_DATASEG(get_seg_entry(sbi, segno)->type)) {//不是data segment,则需要进行FSCK修复 set_sbi_flag(sbi, SBI_NEED_FSCK); f2fs_warn(sbi, "%s: incorrect segment(%u) type, run fsck to fix.", __func__, segno); err = -EFSCORRUPTED; f2fs_handle_error(sbi, ERROR_INCONSISTENT_SUM_TYPE); goto drop_bio; }
结合上述两种现象,初步推测SSR机制并没有作用在node segment上,而仅对data segment起作用。(目前仅有一个现象支持,且不一定是主要原因,还需要再探索探索)
附:do_garbage_collect 源码
/* do_garbage_collect:选择了victim segment之后,实际运行垃圾回收的函数*/
/* 形参传入: seg_freed = do_garbage_collect(sbi, segno, &gc_list, gc_type,
gc_control->should_migrate_blocks);*/
static int do_garbage_collect(struct f2fs_sb_info *sbi,
unsigned int start_segno,
struct gc_inode_list *gc_list, int gc_type,
bool force_migrate)
{
struct page *sum_page;
struct f2fs_summary_block *sum;
struct blk_plug plug;
unsigned int segno = start_segno;
unsigned int end_segno = start_segno + sbi->segs_per_sec;
int seg_freed = 0, migrated = 0;
unsigned char type = IS_DATASEG(get_seg_entry(sbi, segno)->type) ?
SUM_TYPE_DATA : SUM_TYPE_NODE;
int submitted = 0;
if (__is_large_section(sbi))
end_segno = rounddown(end_segno, sbi->segs_per_sec);
/*
* zone-capacity can be less than zone-size in zoned devices,
* resulting in less than expected usable segments in the zone,
* calculate the end segno in the zone which can be garbage collected
*/
if (f2fs_sb_has_blkzoned(sbi))
end_segno -= sbi->segs_per_sec -
f2fs_usable_segs_in_sec(sbi, segno);
sanity_check_seg_type(sbi, get_seg_entry(sbi, segno)->type);
/* readahead multi ssa blocks those have contiguous address */
if (__is_large_section(sbi))
f2fs_ra_meta_pages(sbi, GET_SUM_BLOCK(sbi, segno),
end_segno - segno, META_SSA, true);
/* reference all summary page */
while (segno < end_segno) {
sum_page = f2fs_get_sum_page(sbi, segno++);
if (IS_ERR(sum_page)) {
int err = PTR_ERR(sum_page);
end_segno = segno - 1;
for (segno = start_segno; segno < end_segno; segno++) {
sum_page = find_get_page(META_MAPPING(sbi),
GET_SUM_BLOCK(sbi, segno));
f2fs_put_page(sum_page, 0);
f2fs_put_page(sum_page, 0);
}
return err;
}
unlock_page(sum_page);
}
blk_start_plug(&plug);
for (segno = start_segno; segno < end_segno; segno++) {
/* find segment summary of victim */
sum_page = find_get_page(META_MAPPING(sbi),
GET_SUM_BLOCK(sbi, segno));
f2fs_put_page(sum_page, 0);
if (get_valid_blocks(sbi, segno, false) == 0)
goto freed;
if (gc_type == BG_GC && __is_large_section(sbi) &&
migrated >= sbi->migration_granularity)
goto skip;
if (!PageUptodate(sum_page) || unlikely(f2fs_cp_error(sbi)))
goto skip;
sum = page_address(sum_page);
if (type != GET_SUM_TYPE((&sum->footer))) {
f2fs_err(sbi, "Inconsistent segment (%u) type [%d, %d] in SSA and SIT",
segno, type, GET_SUM_TYPE((&sum->footer)));
set_sbi_flag(sbi, SBI_NEED_FSCK);
f2fs_stop_checkpoint(sbi, false,
STOP_CP_REASON_CORRUPTED_SUMMARY);
goto skip;
}
/*
* this is to avoid deadlock:
* - lock_page(sum_page) - f2fs_replace_block
* - check_valid_map() - down_write(sentry_lock)
* - down_read(sentry_lock) - change_curseg()
* - lock_page(sum_page)
*/
if (type == SUM_TYPE_NODE)
submitted += gc_node_segment(sbi, sum->entries, segno,
gc_type);
else
submitted += gc_data_segment(sbi, sum->entries, gc_list,
segno, gc_type,
force_migrate);
/* 暂时是空宏,语句为do{}while(0) */
stat_inc_seg_count(sbi, type, gc_type);
sbi->gc_reclaimed_segs[sbi->gc_mode]++;
migrated++;
freed:
/* 已经完成数据迁移,更新统计信息seg_freed(当前函数的返回值,仅有FGGC关心该信息,BGGC不统计) */
if (gc_type == FG_GC &&
get_valid_blocks(sbi, segno, false) == 0)
seg_freed++;
if (__is_large_section(sbi))
sbi->next_victim_seg[gc_type] =
(segno + 1 < end_segno) ? segno + 1 : NULL_SEGNO;
skip:
f2fs_put_page(sum_page, 0);
}
if (submitted)
/* 提交一个合并的写请求*/
f2fs_submit_merged_write(sbi,
(type == SUM_TYPE_NODE) ? NODE : DATA);
blk_finish_plug(&plug);
stat_inc_call_count(sbi->stat_info);
return seg_freed;
}